

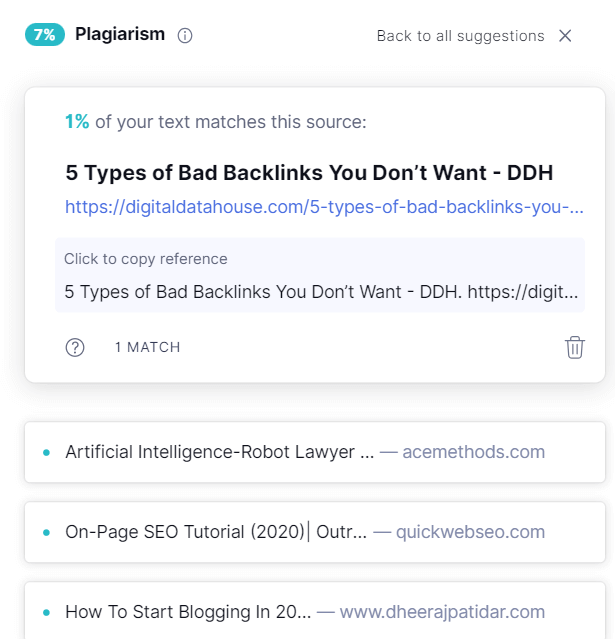
In the world of websites, SEO plays a crucial role in achieving success. One thing that gets in the way of that is duplicate content. RicketyRoo’s put together this guide to duplicate content, its impact on SEO, and effective strategies to handle it when working with clients. Duplicate content is everywhere — let’s do something about it together.
Understanding Duplicate Content
What Is Duplicate Content?
Duplicate content refers to substantial blocks of text that are either exact matches or significantly similar within a single website or across domains. It can take various forms, such as:
- Identical paragraphs
- Identical sentences
- Pages replicated on different URLs simply swapping out a location or service
Types of Duplicate Content
There are two types of duplicate content you’ll encounter:
- Internal Duplicate Content: This occurs when similar or identical content exists within a single website. It may stem from website structure or accidental duplication during the content creation process. In some cases, this content is created on purpose instead of taking the time to create unique pages or blog posts.
- External Duplicate Content: This refers to duplicate content across different websites or domains. It can arise from syndication, content scraping, or content shared on many platforms. Often, content found on sites outside yours or your client’s is because someone stole it somehow. Less often, someone owns a set of domains and chooses to use the same content across the board, not realizing the negative impact it might have.
Duplicate Content and Thin Content

Differentiating between duplicate content and thin content is essential. Duplicate content involves a significant amount of duplicated text, while thin content refers to low-quality, shallow, or insignificant content. Thin content may be unique but lacks substance or value for users.
Read More: Thin Content Shock: Google Can Issue Manual Penalties for Service Area Pages
Google’s Stance on Duplicate Content
Google follows specific guidelines regarding duplicate content. While Google does not impose penalties on non-manipulative or non-deceptive duplicate content, it has mechanisms to handle content it deems duplicate.
Google aims to provide users with valuable search results. Consequently, when faced with duplicate content, Google determines the most appropriate version to display in search results — or not display your page, blog post, or entire website — depending on the amount of duplicate content present.
Google wants to filter out duplicate content whenever possible to serve the best possible answers to every query. This means ensuring that you see different results when you search, not the same URL repeatedly. You can find details in this blog post, which states:
- When we detect duplicate content, such as through variations caused by URL parameters, we group the duplicate URLs into one cluster.
- We select what we think is the “best” URL to represent the cluster in search results.
- We then consolidate properties of the URLs in the cluster, such as link popularity, to the representative URL.

While Google does not penalize duplicate content, it recommends proactive steps to handle it effectively.
By adhering to Google’s recommendations and best practices for handling duplicate content, websites can mitigate the negative impact on their website’s visibility and maintain a strong SEO performance.
Differentiating Between Acceptable and Problematic Duplicate Content
Acceptable Duplicate Content
Sometimes, duplicate content, such as product descriptions on e-commerce websites or legal disclaimers, is intentional and necessary. Google can recognize acceptable duplicate content on websites, but everything is suspect if your website has a substantial amount of duplicate content.
Problematic Duplicate Content

Unintentional or manipulative duplicate content can arise from technical issues, content scraping, or attempts to manipulate search rankings. For instance, scaling location pages by merely replacing the city name while keeping the rest of the content unchanged can harm a website’s SEO performance and user experience.
Duplicate Content and SEO
Duplicate content can significantly impact a website’s visibility, ranking, and overall SEO performance. Exploring this relationship in-depth sheds light on its challenges and the importance of managing duplicate content effectively.
Search Engine Crawling and Indexing
Search engines use crawlers to discover and analyze web pages. These crawlers navigate through links, indexing the content they encounter. Duplicate content poses challenges for search engines during the crawling and indexing process. As we mentioned above about how Google handles these issues, when Google comes across duplicate content, it must determine the most relevant version worthy of indexing.
Confusion in Relevance Assessment
Google strives to show users the most relevant search results. When confronted with duplicate content, search engines may need help determining the most suitable version to display. This confusion can result in search engines ranking one version over another or, in some cases, not ranking any version.
Potential Dilution of Link Equity
Link equity is the value and authority passed from one webpage to another through hyperlinks. Duplicate content across multiple URLs can divide the backlink equity that could have been consolidated into a single page. In this case, the link equity gets diluted, potentially reducing the SEO value of each page. This dilution hinders the ability of those pages to rank well and earn organic traffic. This also renders internal links from these pages useless to other pages throughout a website.
Impact on User Experience
Duplicate content can harm the user experience. When users come across identical or highly similar content on different pages, it can cause confusion and frustration. Visitors may perceive the website as unoriginal, spammy, or low-quality, leading to a loss of trust and credibility. This negative experience can result in increased bounce rates, decreased engagement metrics, and a detrimental impact on user experience.
Importance of Unique and Relevant Content
Search engines prioritize unique and valuable content that caters to users’ needs. By consistently creating original and relevant content, websites will distinguish themselves and avoid the pitfalls of duplicate content. Providing unique content helps search engines understand the distinctiveness and value of a website, leading to better visibility, improved rankings, and increased organic traffic.
We’re living in an E-E-A-T world — our content needs to catch up.
Understanding the relationship between duplicate content and SEO underscores the challenge of ensuring a client’s content is appropriately indexed, ranked, and presented to users. By addressing the potential confusion and dilution caused by duplicate content and creating unique, high-quality content, websites can enhance their SEO efforts and improve overall performance and visibility in search engine results.
12 Ways to Avoid Duplicate Content
Ideally, you’re avoiding duplicate content to begin with. Here are some tips for doing just that:
- Understand your CMS: Familiarize yourself with how content is displayed on a website, especially if it incorporates a blog, forum, or similar system that presents content in multiple formats.
- Embrace uniformity: Strive for consistency in internal linking by avoiding variations such as /page/, /page, and /page/index.htm.
- Set canonicals: These tags are crucial in avoiding duplicate content issues on a website. Specifying the preferred version of a web page’s content allows websites tell search engines the primary or original page that should be indexed and ranked. This takes the guesswork out of Google’s hands and puts it back into yours.
- Have a dev site? Check it!: Placing a website under development on a subdomain helps keep it hidden, but a single public link can lead to search engine indexing causing duplicate content issues for your production domain. Ensure you set your dev site to noindex or password-protect it to keep it from being indexed.
- Ensure pagination isn’t an issue: Websites can implement several strategies, such as using canonical tags to indicate the preferred version of the content, implementing rel=”next” and rel=”prev” tags to guide search engines through paginated series, and employing the “view all” option to consolidate content onto a single page.
- Syndicate with caution: If you syndicate your content, ensure they include a backlink to the original article with each syndicated piece. This is another area to consider canonical URLs to point to the source.
- Streamline repetitive content: Rather than including extensive copyright text at the bottom of every page and other reused information, consider a page to link to versus sharing everything over and over across a website.
- Stop printer-friendly pages from creating a second page or blog post: To avoid this problem, websites should use canonical tags to indicate the primary version of the content and prevent search engines from indexing the printer-friendly pages. Depending on your website theme, you may be able to use CSS to hide the printer-friendly version from search engine crawlers.
- Avoid empty placeholders: Enhance the user experience by refraining from publishing or blocking pages lacking substantial content. This ensures users and bots are not confronted with countless instances of the same content page after page.
- Leverage top-level domains (TLDs): Enhance Google’s ability to serve the most relevant document version by using top-level domains whenever feasible, especially when handling country-specific content.
- Use hreflang for language and regional URLs: If your site has content in multiple languages, use the hreflang attribute to tell search engines about the different versions of your pages.
- Utilize Google’s preferred domain feature: If other sites link to your website using the www and non-www versions of your URLs, you can inform Google about your preferred indexing preference through Google Search Console.
Managing Duplicate Content for SEO Success
While duplicate content can impact SEO performance, effective management ensures optimal results. It’s important to note that duplicate content does not inevitably lead to SEO damage. The impact depends on various factors.
You can ensure optimal SEO performance by prioritizing original content creation and implementing effective handling strategies like canonical URLs, 301 redirects, and consistent internal linking.
Always remember that creating valuable and unique content should be the cornerstone of your SEO efforts. At RicketyRoo, we uphold this principle every day and encourage everyone to invest in creating high-quality, unique content — no matter what you’re optimizing.
Need help detecting dupes?
Schedule a discovery call with RicketyRoo
and find out how we can take your content to the next level.